
For the past while I’ve been working on a major redesign of my high performance gpu cooler project.
The rapid ascent of the LLM into the collective consciousness has sent the big players into a frenzy over datacenter GPUs. This is putting accelerating downward pressure on the price of all used compute GPUs, even the historically pricey stuff. P100s can be had for ~$100, V100 16GB are selling for ~$500, any day now the lower VRAM Ampere cards are going to drop below $1000…
We need a new cooler that can support any of these 300W GPUs, can be installed as densely as the cards, and is easy on the ears for homelab use. Pictured below are four prototype coolers installed on Tesla P100s:




Like always, if you’re interesting in beta testing one of these coolers, send me a note. I’ve been keeping a list of people that have reached out since the original post and will likely be sending out a batch of coolers for feedback early next year.
Endgame EOL’d GPU Box?
Nominally out of date, the X99 Intel E5-* Xeon CPUs remain a favorite among homelabbers. CPUs are cheap, and the cores are plentiful. Relevant to the engineer interested in local LLM usage is the fact that that many of the workstation-class motherboards for these CPUs can mechanically support four x16 GPUs without breaking the bank.
In my mind, the Kepler, Maxwell and Pascal (to a lesser extent) series of NVidia compute GPUs sit in the same place. Irrelevant to volume businesses but potentially useful to small shops with specialized workloads.
In a way, I’ve been building up to a system like this for a while but having a suitable GPU cooler has remained the limiting factor. There are also a bunch of amazing builds out there covering similar ground but I feel they probably ran into the same cooling-related problems I did. Now that the new cooler has matured to a working prototype, I can finally build this system and see how much performance we can squeeze out of these old parts.
Benchmarking
In service of the cooler project, my collection of these enterprise GPUs is nearly the full set from Kepler to Pascal. I have a few motherboards and CPUs that fit the bill as well to make a benchmarking effort worthwhile. These are the different hardware combinations I plan on trying:
GPUs:
- 1x, 2x, 3x K80 (Will cause PCIe speed downgrades)
- 1x M10
- 1x M40
- 1x M60
- 1x M40 + 1x M60
- 1x P40
- 1x, 2x, 3x, 4x P100 (Will cause PCIe speed downgrades)
- 1x V100
- 1x V100 + 1x P100
I’ll re-run the interesting results from the above sets of hardware on these different CPUs to see what changes:
CPUs:
- Intel Xeon E5-2687W v4 12-Core @ 3.00GHz (40 PCIe Lanes)
- Intel Xeon E5-1680 v4 8-Core @ 3.40GHz (40 PCIe Lanes)
As for the actual tests, I’ll hopefully be able to come up with an ansible playbook that runs the following:
- vLLM throughput with llama3-8b weights
- Folding@Home, BIONIC, Einstein@Home and Asteroids@Home
- ai-benchmark.com
- llama-bench
- I’ll probably also write something to test raw ViT throughput as well.
Without running anything, I’d bet that all of this effort is going to tell us what we already know:
- The later generation GPUs will perform better.
- Adding more GPUs does increase performance but with diminishing returns.
Still though, I’d like to have some hard numbers before saying anything authoritatively.
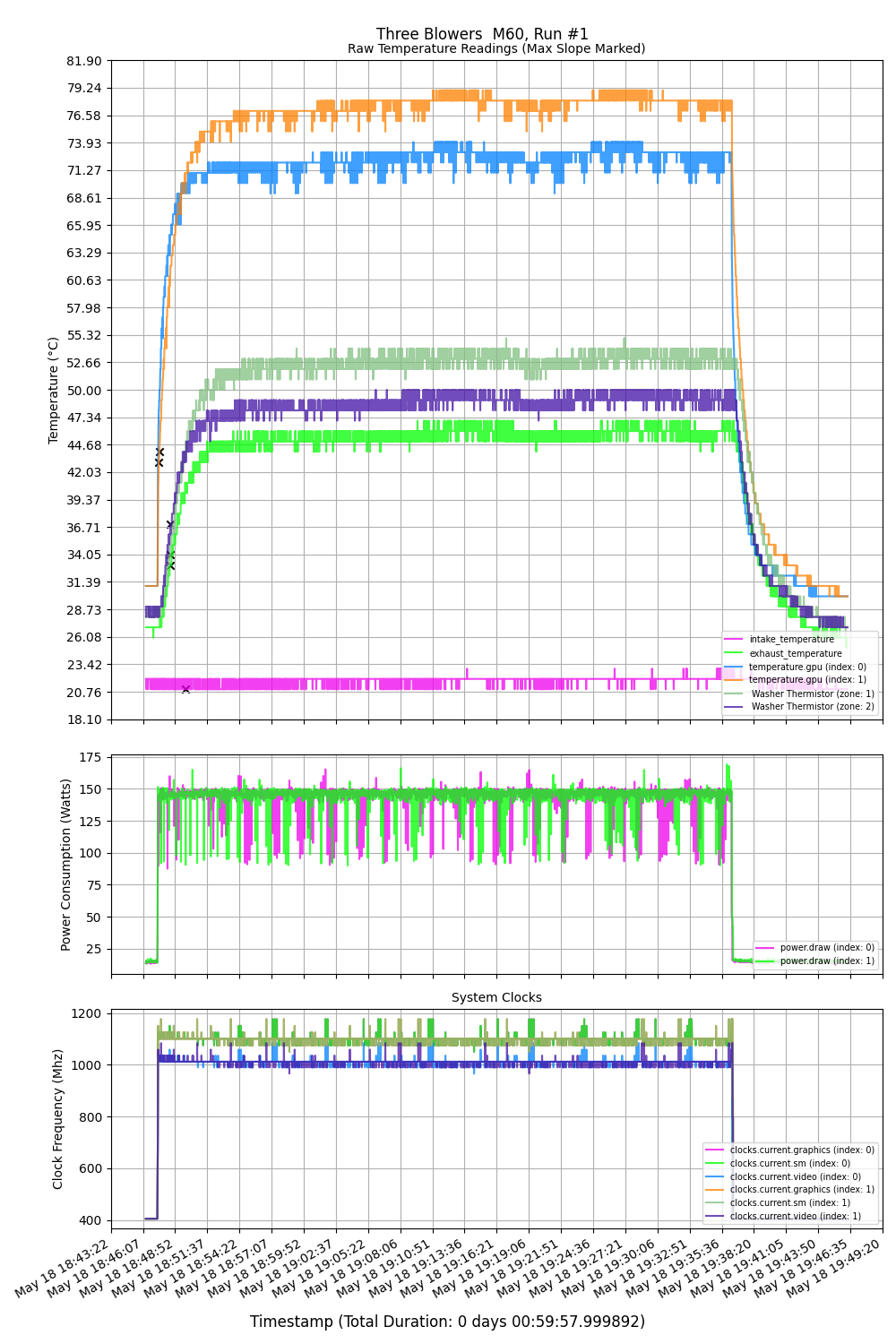
All of this testing will also yield a lot of relevant data to the larger cooler project. One of the most complicated issues in the design is the process of going from the external temperature of the GPU to the internal core temperature. It is absolutely possible to model the relationship. Physical or numerical models, regression models, random forest models etc are all effective at doing the conversion. These methods require a lot of real-world data for training or testing. I’ve been harvesting this data for this purpose pretty much as long as I’ve run the compute cards in my lab:




This benchmarking project, as well as the subsequent server build with the winning config is a great source for this modeling data as well. In this direction, I made a harness to have each of the new coolers talk to the host via USB



The host also records nvidia-smi output so all of the different variables can be compared on the same time series.
See you next time
Unlike a lot of my posts, this one isn’t going to end with links to code or CAD. The cooler has come a long way since the original publication, but is still a work in progress. Regarding the Endgame EOL’d GPU Box, I’ll probably be developing the benchmark and running through the different configs on stream this fall.

Wow I have been led here by your youtube channel I am windows11 guy on YouTube
Thanks! Welcome