Key Learning
Python uses a Global Interpreter Lock to make sure that memory shared between threads isn’t corrupted. This is a design choice of the language that has it’s pros and cons. One of these cons is that in multi-threaded applications where at least one thread applies a large load to the CPU, all other threads will slow down as well.
For multi-threaded Python applications that are at least somewhat time-sensitive, you should use Processes over Threads.
Experiment
I wrote a simple python script to show this phenomenon. Let’s take a look.
def increment(running_flag, count_value):
c = 0
while True:
if not running_flag.value:
break
count_value.value = c # setting a Value is atomic
c += 1
The core is this increment function. It takes in a Value and then sets it over and over, increment each loop, until the running_flag is set to false. The value of count_value is what is graphed later on, and is the measure of how fast things are going.
The other important bit is the load function:
def load(running_flag):
z = 10
while True:
if not running_flag.value:
break
z = z * z
Like increment, load is the target of a thread or process. The z variable quickly becomes large and computing the loop becomes difficult quickly.
The rest of the code is just a way to have different combinations of increment and load running at the same time for varying amounts of time.
Result

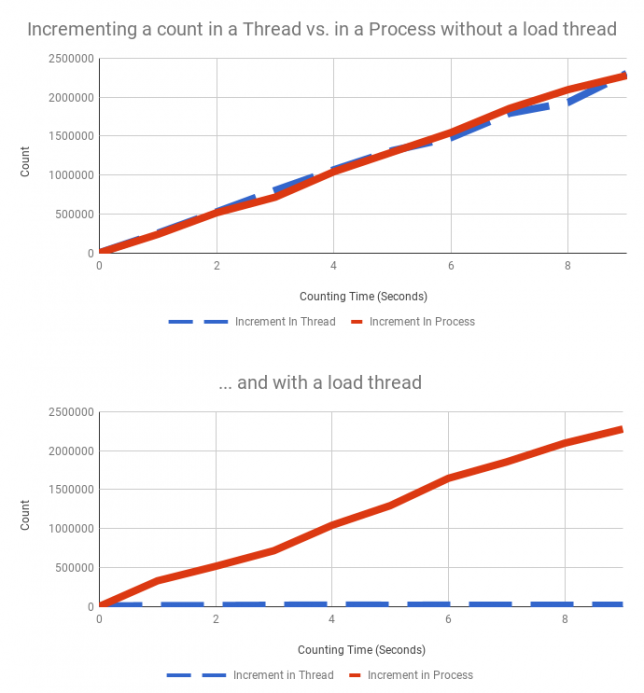
The graph really tells the story. Without the load thread running, the process and thread versions of increment run at essentially the same rate. When the load thread is running, increment in a thread grinds to a halt compared to the process which is unaffected.
That’s all! I’ve pasted the full source below so you can try the experiment yourself.
from multiprocessing import Process, Value
from threading import Thread
from time import sleep
from ctypes import c_bool, c_longdouble
def increment(running_flag, count_value):
"""
Increment the value in count_value as quickly as possible. If running_flag is set to false, break out of the loop
:param running_flag: a multiprocessing.Value boolean
:param count_value: a multiprocessing.Value Long Double
"""
c = 0
while True:
if not running_flag.value:
break
count_value.value = c # setting a Value is atomic
c += 1
def load(running_flag):
"""
Apply a load to the CPU. If running_flag is set to false, break out of the loop
:param running_flag: a multiprocessing.Value boolean
"""
z = 10
while True:
if not running_flag.value:
break
z = z * z
def mct(target, flag, value):
"""
Returns a lambda that can be called to get a thread to increment a increment using a thread
"""
return lambda: Thread(target=target, args=(flag, value))
def mcp(target, flag, value):
"""
Returns a lambda that can be called to get a thread to increment a increment using a process
"""
return lambda: Process(target=target, args=(flag, value))
def mlt(target, flag):
"""
Returns a lambda that can be called to get a thread that will load down the CPU
"""
return lambda: Thread(target=target, args=(flag,))
if __name__ == "__main__":
f = Value(c_bool, True) # control flag, will be passed into child thread/process so they can be stopped
cv = Value(c_longdouble, 0) # increment value
child_lists = [mct(increment, f, cv)], [mcp(increment, f, cv)], [mct(increment, f, cv), mlt(load, f)], [mcp(increment, f, cv), mlt(load, f)]
for delay in range(10): # maximum run time of 10 seconds
max_counts = []
for get_children in child_lists:
# reset the flag and increment
f.value = True
cv.value = 0
# the child thread/processes will end up in here
children = []
for get_child in get_children:
child = get_child() # create a new instance of the thread/process to be launched
child.start()
children.append(child)
sleep(delay)
f.value = False
for child in children:
child.join() # stop the process
max_counts.append(cv.value)
s = ""
for count in max_counts:
s += str(count) + " "
print(s)