
This post is one in a series about GANce
Close-readers, twitter-followers and corporeal-comrades will have already beheld the good news that Won Pound by Won Pound has been released! This is Won’s second album-length project (first of course being Post Space released in 2018), and graces listener’s ears courtesy of Minaret Records, a California jazz label.
The record is accompanied by an album-length music video synthesized with GANce, containing a completely unique video for each track. These 93960 frames have been the ultimate goal of this project since it’s inception, and serve as the best demonstration as to what GANce can do. Within the video (linked below), the video for ‘buzzz’ is a personal favorite, demonstrating the three core elements of a projection file blend:
Even thought it’s included in the album-length, there’s a standalone video for NOVA as well, released as the lead single for the project:
The album cover (the header image for this post) was also synthesized from one of the networks trained for the project. Here’s the same latent vectors passed through different networks created during the training process. You can see how the network ‘learns’ what a photo of Won should look like:




















I wrote the following describing how these visuals connect with the music:
The accompanying visuals build on the record’s sonic thesis of painstaking self-exploration. What began with the desire to create an album cover with AI ballooned into an album-length, synthetic video self-portrait. The music is transformed, blended with reverse-synthesized images, then piped directly into the neural network. This technique yields video that is a new and unique visual form, a true coalescence of Won Pound’s visual identity and his music.
Changes since previous update
The implementation of overlays remained as the last feature work that would appear in the videos. Still though, the process of making sure the resulting assets were the highest quality possible was non-trivial. Picking up Vidgear enabled finer control over the output encoding. Research uncovered the best ffmpeg settings for exporting a 4k video to YouTube, which were then implemented in the standard frame -> video writer used all over GANce.
Since the output frames from the StyleGAN2 network are 1024×1024, and the target resolution of the production assets was 2160×2160, some care had to be taken in upscaling the frames. This seems to be a common trap for new players, so pardon my ignorance. OpenCV’s default image scaling method is linear, which is fast but not maximally good-looking (accurate? honest? pleasant?). Since the video doesn’t have to be written out in real time (yet), we can use Bicubic scaling. I was shocked to be able to visually see the difference here. This is the video for ‘NOVA’ with frames upscaled using the linear method:
Compared to the video for ‘NOVA’ upscaled with the bicubic method:
Okay so maybe the difference is more subtle than I let on, but if you full-screen, there is a clear difference. File size is better indicator of the slight increase in quality. The two videos were encoded with the exact same settings, but the linear weighs in at 638 MB and the Bicubic at 721 MB. Almost 100 MB of quality for free!
What is next (GANce live)
Realtime synthesis has always been theoretically possible, as the process of going from latent vectors -> synthesized images can be done at ~9 FPS on a single Tesla K80 core. Having known this for some time, it’s been a software design mantra of mine to build everything in the video rendering pipeline around python generators, so that one day the video can be written to a projector on a stage rather than an mp4 file. Imagining turning the audio gain parameters way up and switching between a few networks during a performance gives me goosebumps.
Since the release of Won Pound, I’ve been actively working toward proving out this concept. I’m happy to report that with two K80s steaming along in parallel, video can be produced at a palatable 30FPS. Having a plain square on a project is a bit less than ideal, so they’ll be some more work to add a few more tricks to the basket. I’m thinking of changing the size and position of the frame as well, maybe overlaid on top of a live video of the room? Who knows.
Live hardware
Mechanically, brining GANce to the stage will also require revisiting the hardware. This will be detailed in a future post, but I’ve built out a GPU-only box built to travel.

Unfortunately, as was foretold in the introductory post, I’ve also had to rethink the GPU cooler again to be quieter and more responsive to sudden changes in temperature. I’m also taking this opportunity to make it quieter as well, as those 40mm fans at full speed get annoyingly loud. There have also been a few inquires wondering if I’d sell kits or assembled units of the coolers. This redesign will hopefully also make this possible, selling a bespoke hardware product like this has always been a dream of mine.
If you’re in New England, they’ll hopefully be a few Won Pound shows coming up that feature live GANce visuals. Won’s twitter would be the best place to watch for details.
Origin Story
There’s been a bit of commentary on the development history of this project so far, but nothing detailing the earliest days of this now yearlong effort. So, to conclude this post; a short historical digression.
By September of 2020, Won had a few demos for his untitled next project. The sound he’d tapped into clearly had the legs to be an album. He played me the demos and solicited opinions on art direction. We’d both independently happened onto thispersondoesnotexist.com, and upon leafing through the GitHub and seeing my native Python, I agreed to start development on a self-portrait synthesized with this technology.
To prove the concept, I started by writing a script to periodically capture pictures while sitting at my desk:



This script ran in the background for a few days and ended up capturing ~65K bleak-looking selfies. Initially these were fed into the stylegan2-pytorch implementation, because I couldn’t get the original StyleGAN2 repo working on my windows machine. This produced some moderately interesting results:

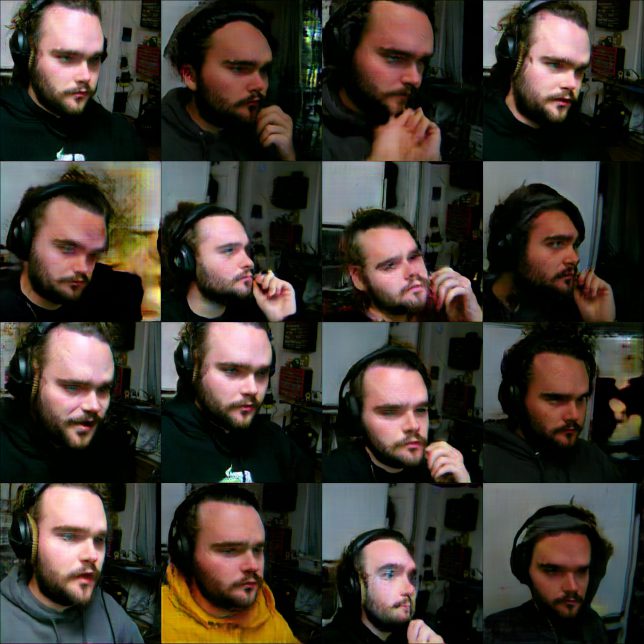
Directionally, these initial syntheses proved the concept and then some. What strange images, they were photos of me but they weren’t really me. They early images looked like a soup of hair and skin and eyes. Pounds thought the same, and with me for a holiday visit, I brought a nascent version of a pitraiture setup. Throughout that winter, Won would capture many thousands of images in the same style that I had captured mine. Working in the studio, while reading, playing games etc. This was a mistake, as the resulting images were all over the place.




We captured around 32K images with in this style, and then trained a network. This whole process took about two months, and by the end of March we had a real network to start playing with. Garbage in, garbage out held, and our undirected inputs produced undirected outputs. With this valuable lesson learned Won began capturing more dynamic images, with the goal of keeping his face in the frame, and making sure the shot was well lit with natural light.




Additionally, these images would be filtered down to only those that contained faces. This way, the inevitable misses wouldn’t make their way into the output. By the end of that summer, the second long term training job would begin using this new set of ~50K images. The training would last two months, into September of 2021.
In parallel with the business of capturing images and training networks, I started poking around to see what else we could squeeze out of this new technology. The realization that it’d be trivial to pipe music into the networks came soon after understanding how to work with the networks to produce any images at all. Here’s one of the very first videos that is representative of this concept, from June of 2021:
Of course, getting the full audio -> video pipeline working ended up being more complicated than I’d expected (what isn’t). The resulting videos were cool, but weren’t interesting enough to last the full length of the album. Circling back to the StyleGAN2 original paper is what got me thinking about projection and how this could be used to steer the resulting videos. Again, coming up with a repeatable way to project many thousand images and store the results also proved to be very complicated. Won shot and edited the full 27 minute input video by himself over a period of four months from October of 2021 to January of 2022. He’d send a video and I would feed it into the projector code, producing the massive projection files.
These files, like the project at large are very storage-intensive. Like I mentioned in the introductory post, Won and I have used a self-hosted ownCloud instance to move files back and forth. As I write this, the project folder is 1.17 TB on disk. The scratch folder on my NAS, which contains backups of the networks, face images .tfrecords files, as well as thousands of album-length videos representing different parameter sets weighs in at 1.2 TB.
Anyways, once the videos were shot and projected it was another period of tweaking and waiting. Understandably, the release of the album got shuffled around due to conditions out of everyone’s control. Each time this’d happen, a pocket of time was created, allowing for more ideas to be explored. This cycle ended in April of 2022 with the release of NOVA.
Even though the wall time from start to finish was a year and seven months, so much of this project was sitting around and waiting. Waiting for a network to be trained, waiting for a projection file to be created, waiting for an output video to render etc. I would estimate that had I worked on this full-time, it would have taken two solid months to write the software a complete the research for creating these videos.
Obviously both of us have real jobs and lives to attend to, but still we were able to produce this very large piece of work over a very long period of time. It was a great change of pace, working without a deadline or rigid requirements. My involvement with Won Pound by Won Pound has affirmed my love for working with artists. Using engineering techniques to build on ideas. I would also like to publicly thank Mr. Pound for constantly giving feedback and being patient during the development process, as well as trusting me with such a large piece of his visual brand.

Hey people!!!!!
Good mood and good luck to everyone!!!!!